W/o CM & Interaction Correction
Without Communication Module (CM) and Interaction Correction, the model can not effectively learn spatial relations between humans and objects.
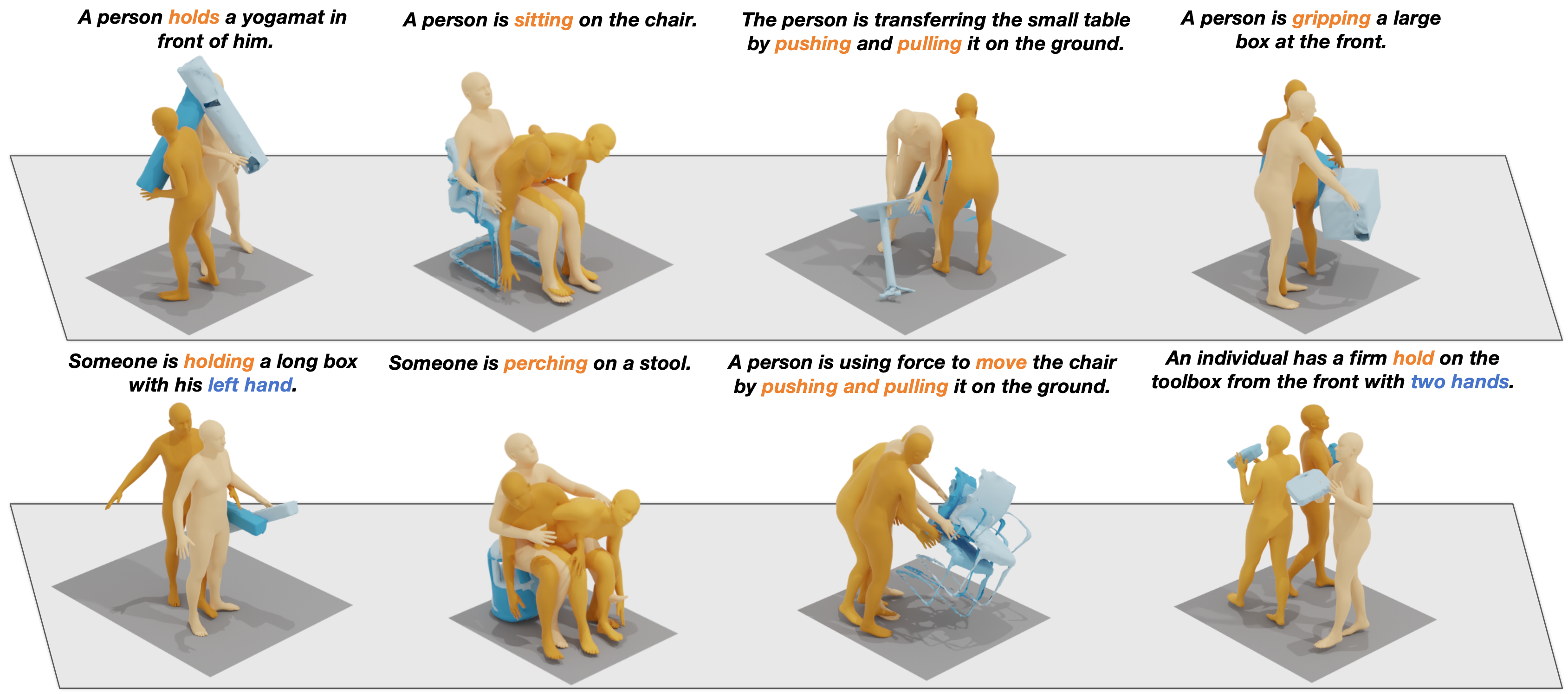
We address the problem of generating realistic 3D human-object interactions (HOIs) driven by textual prompts. To this end, we take a modular design and decompose the complex task into simpler sub-tasks. We first develop a dual-branch diffusion model (HOI-DM) to generate both human and object motions conditioned on the input text, and encourage coherent motions by a cross-attention communication module between the human and object motion generation branches. We also develop an affordance prediction diffusion model (APDM) to predict the contacting area between the human and object during the interactions driven by the textual prompt. The APDM is independent of the results by the HOI-DM and thus can correct potential errors by the latter. Moreover, it stochastically generates the contacting points to diversify the generated motions. Finally, we incorporate the estimated contacting points into the classifier-guidance to achieve accurate and close contact between humans and objects. To train and evaluate our approach, we annotate BEHAVE dataset with text descriptions. Experimental results on BEHAVE and OMOMO demonstrate that our approach produces realistic HOIs with various interactions and different types of objects.
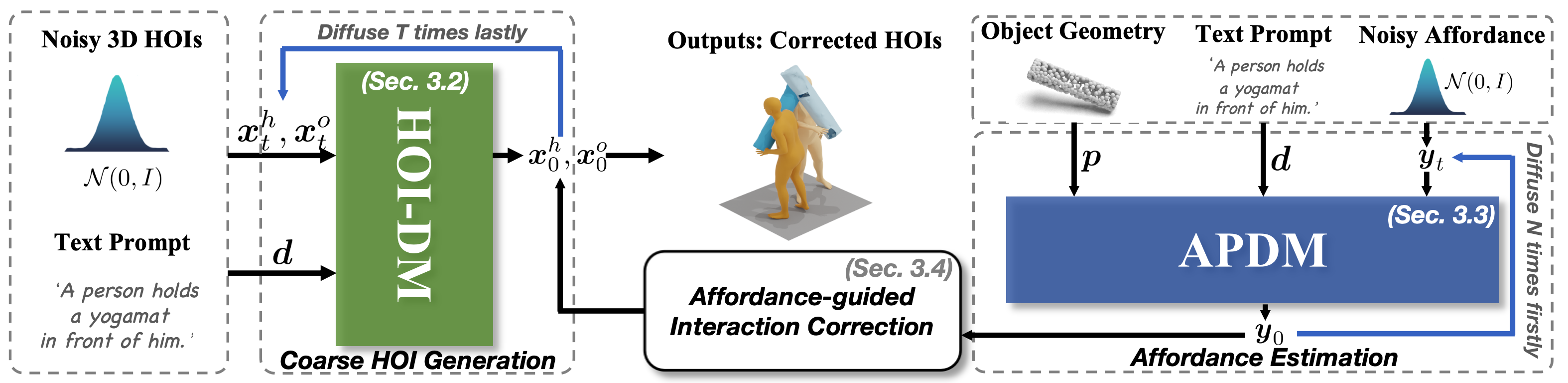
Our key insight is to decompose the generation task into three modules: (a) coarse 3D HOI generation using a dual-branch diffusion model (HOI-DM), (b) affordance prediction diffusion model (APDM) to estimate the contacting points of humans and objects, and (c) afforance-guided interaction correction, which incorporates the estimated contacting information and employs the classifier-guidance to achieve accurate and close contact between humans and objects to form coherent HOIs.
Without Communication Module (CM) and Interaction Correction, the model can not effectively learn spatial relations between humans and objects.
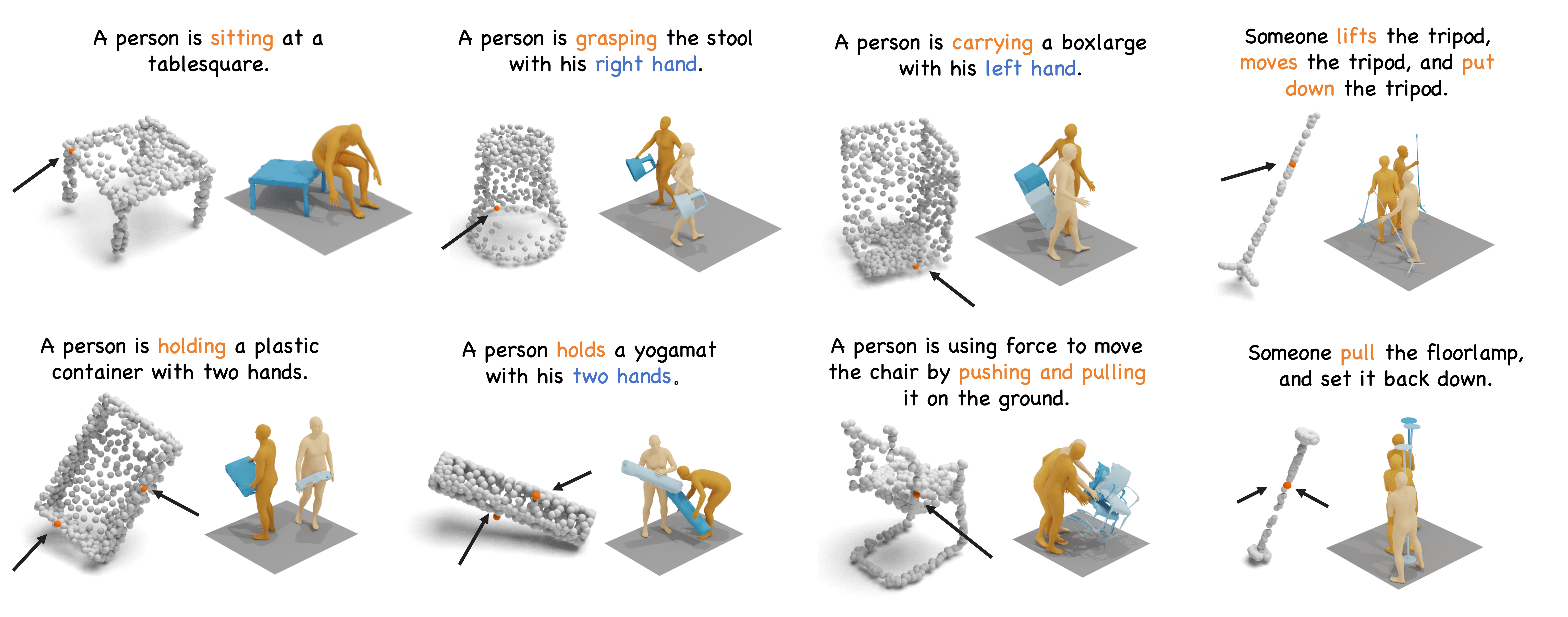
Without Interaction Correction, the generated HOIs cannot follow the accurate and close human-object contacting, yielding unreal and incoherent interactions.
The visualization validates that our complete model significantly outperforms in generating both realistic and accurate human-object interactions.
@article{peng2023hoi,
title={HOI-Diff: Text-Driven Synthesis of 3D Human-Object Interactions using Diffusion Models},
author={Peng, Xiaogang and Xie, Yiming and Wu, Zizhao and Jampani, Varun and Sun, Deqing and Jiang, Huaizu},
journal={arXiv preprint arXiv:2312.06553},
year={2023}
}